
Construindo um Pipeline de Dados Moderno no Databricks!
- Michel Souza Santana
- 15 de out. de 2025
- 4 min de leitura

Olá, comunidade de dados!
Nos últimos anos, a engenharia de dados evoluiu de simples scripts de extração para ecossistemas complexos que exigem governança, escalabilidade e, acima de tudo, automação. Processos manuais não são apenas ineficientes; eles são um risco para a consistência e a agilidade que o negócio moderno exige.
Estou animado para compartilhar um projeto que finalizei recentemente, onde construí um sistema de engenharia de dados completo, aplicando as práticas mais avançadas do mercado. O desafio? Criar um pipeline ETL robusto, escalável e totalmente automatizado. O resultado? Uma solução end-to-end que transforma dados brutos em insights valiosos de forma eficiente e governada.
Neste artigo, vamos mergulhar na arquitetura e nas tecnologias que tornaram isso possível.
O Alicerce: Arquitetura Medallion para Qualidade e Governança
Antes de escrever qualquer linha de código, a primeira decisão foi estrutural. Adotar a Arquitetura Medallion foi fundamental para garantir que os dados evoluíssem de forma controlada e confiável através do pipeline.
Essa abordagem organiza os dados em três camadas lógicas:
Bronze (Raw): A primeira parada para os dados brutos. Aqui, os dados são armazenados em seu formato original, imutáveis. Esta camada serve como um registro histórico e nos permite reprocessar todo o pipeline a qualquer momento, sem precisar acessar a fonte novamente.
Silver (Trusted): Nesta camada, a mágica começa. Os dados da camada Bronze são limpos, filtrados, padronizados e enriquecidos. Garantimos tipos de dados corretos, tratamos valores nulos e aplicamos as primeiras regras de negócio. O resultado é um conjunto de dados confiável e pronto para ser consumido por diversas áreas.
Gold (Refined): A camada final, onde os dados são agregados e modelados para atender a casos de uso específicos de negócio, como dashboards de BI, relatórios analíticos ou features para modelos de Machine Learning.

Construção Declarativa com Delta Live Tables (DLT)
Com a arquitetura definida, a próxima escolha foi a ferramenta para construir os pipelines. Em vez de scripts Spark tradicionais, optei pelo Delta Live Tables (DLT).
O DLT é um framework que simplifica o desenvolvimento ETL. Em vez de se preocupar com a orquestração de tarefas, gerenciamento de clusters e infraestrutura, você apenas declara as transformações de forma declarativa (em SQL ou Python).
Por que DLT?
Simplicidade: Reduz drasticamente o código boilerplate. Você foca na lógica de transformação.
Qualidade de Dados Integrada: Permite definir "expectations" (regras de qualidade) diretamente no pipeline. Você pode instruir o DLT a descartar, alertar ou interromper o fluxo caso os dados não atendam aos critérios.
Evolução de Schema Automática: Lida com mudanças no schema dos dados de origem, evitando que os pipelines quebrem.
Exemplo Prático: Definindo uma tabela Silver com DLT
Vamos imaginar que estamos limpando uma tabela de clientes da camada Bronze.
Explicação: O código abaixo cria uma tabela customers_silver a partir da customers_bronze. Ele aplica uma regra de qualidade (valid_email) que espera que o campo de e-mail não seja nulo. Se a regra falhar, os registros serão descartados.
Exemplo:
Python
import dlt
from pyspark.sql.functions import col, trim
@dlt.table(
comment="Tabela de clientes limpa e validada."
)
@dlt.expect_or_drop("valid_email", "email IS NOT NULL")
def customers_silver():
return (
dlt.read("customers_bronze")
.select(
col("id").alias("customer_id"),
trim(col("name")).alias("customer_name"),
col("email"),
col("signup_date")
)
)
Análise do Resultado: Com esse simples bloco de código, o DLT gerencia o grafo de dependências, provisiona a infraestrutura e garante a qualidade dos dados, tudo de forma automática.
Automação e Reprodutibilidade: IaC e CI/CD
Um pipeline de dados moderno não pode depender de deploys manuais. Para automatizar o ciclo de vida do projeto, combinei duas práticas essenciais:
Infraestrutura como Código (IaC) com Databricks Asset Bundles: Toda a configuração do projeto — os notebooks do DLT, as definições de jobs e as permissões — foi definida em arquivos de configuração (.yml). Esses arquivos são versionados no Git junto com o código. Isso garante que qualquer pessoa da equipe possa replicar o ambiente e os pipelines de forma consistente com um único comando.
CI/CD com GitHub Actions: Criei uma esteira de automação que valida e implanta qualquer alteração no código. O fluxo é simples e poderoso:
Um desenvolvedor envia uma alteração (git push) para a branch main.
O GitHub Actions é acionado automaticamente.
A esteira executa um comando databricks bundle validate para garantir que a configuração está correta.
Se a validação passar, o comando databricks bundle deploy é executado, atualizando os recursos no workspace do Databricks.
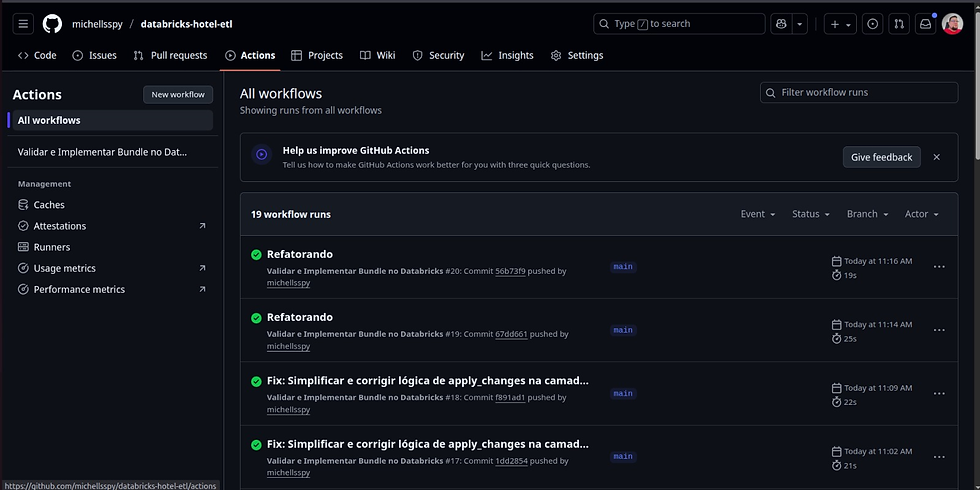
Chega de "funciona na minha máquina"! O CI/CD garante que o ambiente de produção reflita exatamente o que está na base de código principal.
Processo automatizado: do push no Git à implantação no Databricks.
Orquestração Final com Databricks Workflows
Finalmente, para garantir que as camadas Bronze, Silver e Gold sejam executadas na ordem correta e de forma interdependente, utilizei o Databricks Workflows. O Asset Bundle que criei define um único Job orquestrador que encadeia a execução dos pipelines DLT. Isso nos dá uma visão centralizada de todo o fluxo, facilitando o monitoramento, os alertas e o reprocessamento em caso de falhas.
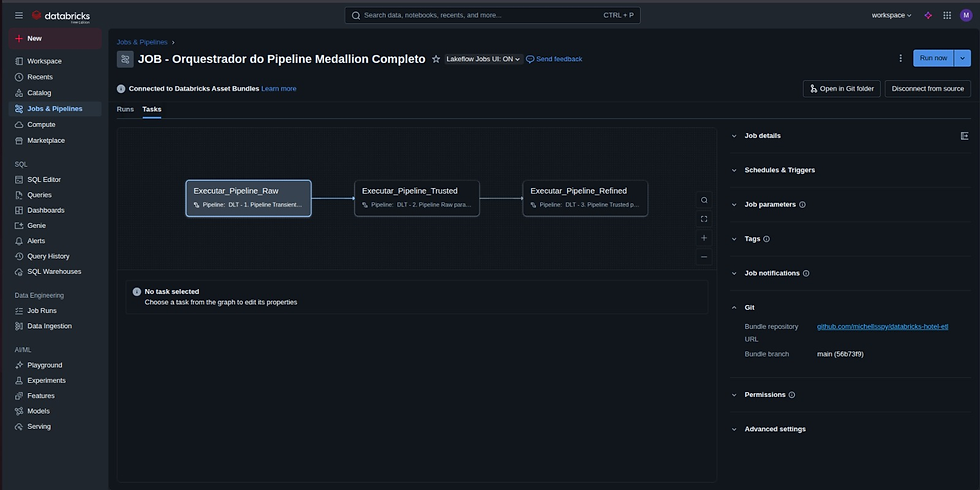
Explore o Projeto na Prática!
Este projeto foi uma imersão fantástica nas capacidades serverless do Databricks e na filosofia de automação total, aplicando conceitos de DataOps e MLOps ao dia a dia da engenharia de dados. A combinação dessas ferramentas não apenas aumenta a eficiência, mas também a confiabilidade e a governança de todo o ecossistema de dados.
🔗 Quer ver o código? O repositório completo, contendo toda a estrutura de pastas, os pipelines DLT e o workflow de CI/CD, está disponível no meu GitHub. O projeto utiliza um dataset público de reservas de hotel para demonstrar o processo de ponta a ponta.
Fique à vontade para clonar, testar e me dar seu feedback! Acredito que a melhor forma de aprender é colocando a mão na massa.
Espero que esta visão geral tenha sido útil. A automação não é mais um luxo, mas uma necessidade para quem busca construir soluções de dados que geram valor real e contínuo.
Até a próxima!



Comentários