
Dados Operacionais vs. Dados Analíticos
- Michel Souza Santana
- 12 de nov de 2025
- 4 min de leitura

Fala, pessoal! Aqui é o Michel Santana.
Quando a gente começa a mergulhar de cabeça no universo da Engenharia de Dados, uma das primeiras coisas que precisamos internalizar é que nem todo dado é criado igual. Parece óbvio, eu sei, mas a forma como gerenciamos, armazenamos e processamos informações para rodar um sistema é drasticamente diferente da forma como as tratamos para gerar insights estratégicos.
É aí que entra a distinção crucial entre Dados Operacionais e Dados Analíticos.
Lembro-me do meu início, tentando entender por que cargas d'água precisávamos de dois tipos de banco de dados completamente diferentes para, no final, olhar para a mesma informação. A clareza só veio com a experiência prática, e é exatamente essa perspectiva que quero compartilhar com vocês hoje.
Vamos descomplicar e entender o que cada tipo de dado significa para o nosso trabalho diário e para o futuro da nossa arquitetura.
1. ⚙️ Dados Operacionais: O Coração Pulsante do Negócio
O dado operacional é o que faz o motor da empresa funcionar no dia a dia. Pense neles como o registro imediato de tudo que está acontecendo agora.
Conceito
Dados operacionais são as informações transacionais geradas por sistemas de produção (OLTP – Online Transaction Processing).
Eles são otimizados para:
Alta Velocidade de Escrita e Leitura (Transações Rápidas): Inserir um novo pedido, atualizar um endereço, debitar um valor.
Consistência (ACID): Garantir que cada transação seja processada perfeitamente.
Pouca Latência: A resposta precisa ser instantânea para o usuário final.
Exemplo Prático
Sabe aquele seu carrinho de compras em um e-commerce? A tabela que registra:
ID do Pedido, ID do Cliente, Status do Pedido (Em Processamento), Data e Hora.
Onde vivem: Geralmente em bancos de dados relacionais (PostgreSQL, MySQL, SQL Server) ou, em arquiteturas mais modernas e escaláveis, em bancos NoSQL ou de baixa latência.
Implicação na Engenharia
Como Engenheiro de Dados, você não atua diretamente nessas tabelas operacionais, mas sim na extração delas. Você precisa de ferramentas que consigam ler esses dados de forma incremental e eficiente, sem derrubar a performance do sistema de produção.
Ferramentas comuns: CDC (Change Data Capture) para capturar as alterações em tempo real ou quase real.
2. 📊 Dados Analíticos: A Bússola Estratégica
O dado analítico é o resultado da transformação dos dados operacionais, com a adição de outras fontes, para que possam ser usados para tomada de decisão e descoberta de padrões.
Conceito
Dados analíticos são as informações históricas e sumarizadas otimizadas para consultas complexas e de grande volume (OLAP – Online Analytical Processing).
Eles são otimizados para:
Alta Velocidade de Leitura (Consultas Complexas): Analisar o volume total de vendas no último trimestre, segmentar clientes por região e idade.
Disponibilidade e Resiliência: O histórico precisa estar sempre lá, pronto para ser fatiado.
Otimização por Coluna: Onde a análise de grandes blocos de dados de uma única coluna é super rápida.
Exemplo Prático
As tabelas que construímos e que são consultadas pelo time de BI (Business Intelligence) ou Data Science. Elas respondem a perguntas como:
Qual a taxa de conversão de pedidos nos últimos 6 meses, comparada com o ano anterior?
Onde vivem: Geralmente em Data Warehouses (Google BigQuery, AWS Redshift, Snowflake) ou Data Lakes e Lakehouses (Databricks, S3/ADLS com Delta Lake).
Implicação na Engenharia
Este é o nosso playground! Nosso papel é construir os pipelines de dados que movem e transformam os dados operacionais (e outras fontes) para o formato analítico. Isso envolve:
Extração (E): Pegar o dado operacional.
Transformação (T): Limpar, enriquecer, padronizar e modelar (estrelas, snowflakes, data vaults).
Carga (L): Inserir no ambiente analítico.
Ferramentas comuns: Apache Spark/Databricks, Google Cloud Dataflow (baseado em Apache Beam), Azure Data Factory, etc.
💡 A Grande Lição: O Fluxo de Trabalho (Data Pipeline)
A diferença entre os dois tipos de dados não é apenas teórica; é a base da nossa arquitetura. A grande sacada é entender que um Data Pipeline robusto é o que conecta o mundo operacional ao mundo analítico.
Característica | Dados Operacionais | Dados Analíticos |
Objetivo | Suporte às Transações Diárias | Suporte à Tomada de Decisão |
Otimização | Escrita (Insert/Update) | Leitura (Consultas Complexas) |
Tempo | Dados Atuais (Agora) | Dados Históricos e Consolidados |
Estrutura | Normalizada (Para evitar redundância) | Desnormalizada (Para otimizar consultas) |
Exemplo de BD | PostgreSQL, MySQL, Cassandra | BigQuery, Redshift, Databricks (Delta Lake) |
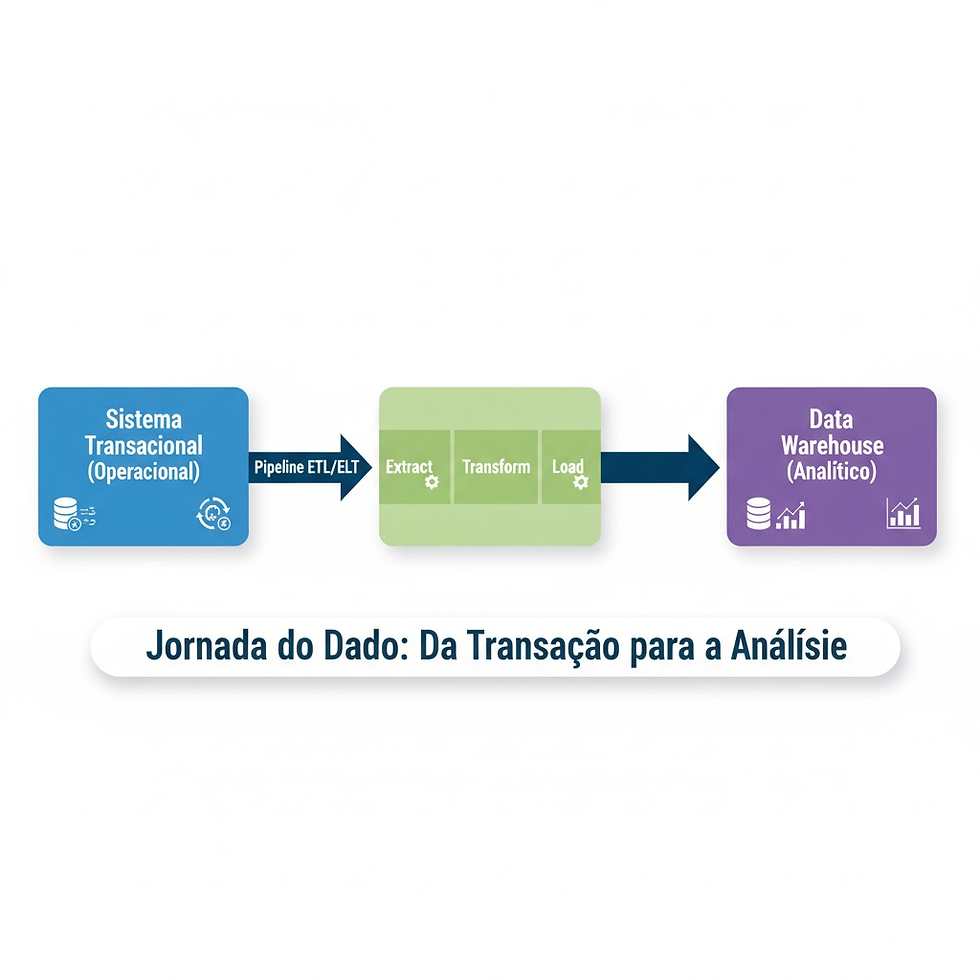
🎯 Conclusão e Insight Final
Se há algo que aprendi trabalhando com grandes volumes de dados é que o maior erro de arquitetura é tentar usar o banco de dados operacional (a tabela de pedidos do sistema) para rodar relatórios pesados. Isso mata a performance do sistema para o usuário e frustra a área de negócios.
A clareza sobre "Operacional vs. Analítico" não é só um conceito de faculdade; é a fundação para projetar pipelines escaláveis e eficientes. Nossa missão como Engenheiros de Dados é justamente ser a ponte, garantindo que o dado chegue limpo, rápido e no formato ideal para que, no final, a empresa possa fazer uma única coisa: tomar decisões melhores.
E aí, como essa distinção é tratada na sua arquitetura? Você já utilizou o conceito de Data Lakehouse (como o Databricks) para tentar unificar essa visão?
Até a próxima, pessoal!



Comentários